
Open LLM Leaderboard 2-Why and How?
As HuggingFace upgraded Open LLM Leaderboard as well as related evaluation benchmarks, we learn why they did that and learn about the new benchmarks.


In June 2024, HuggingFace has announced that its Open LLM Leaderboard is due for an upgrade.
Major problems of LLM Comparison
Most LLM providers do not provide transparency or reproducibility of their claimed scores.
Some might even adjusted their evaluation setup to optimize the scores.
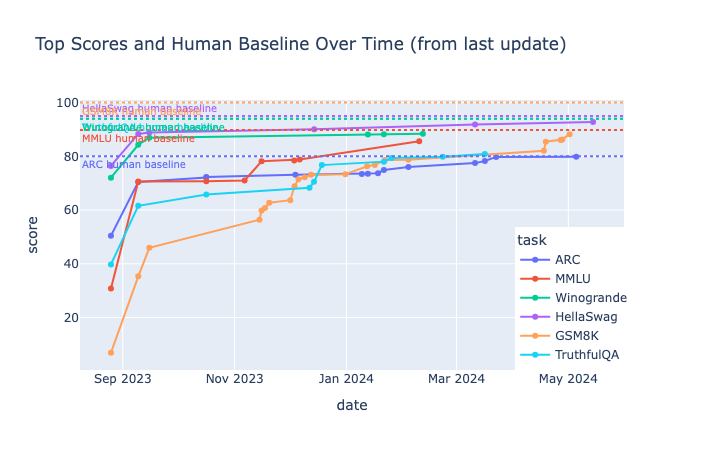
Lately, commonly used benchmarks were ‘saturated’; they become too easy for new models.
Some test benchmarks have leaked into the training of models, a problem of contamination. The models memorize the answer, rather than gaining generalization knowledge.
As research has shown, some benchmarks contain errors, such MMLU and GSM8K.
New Evaluation Method
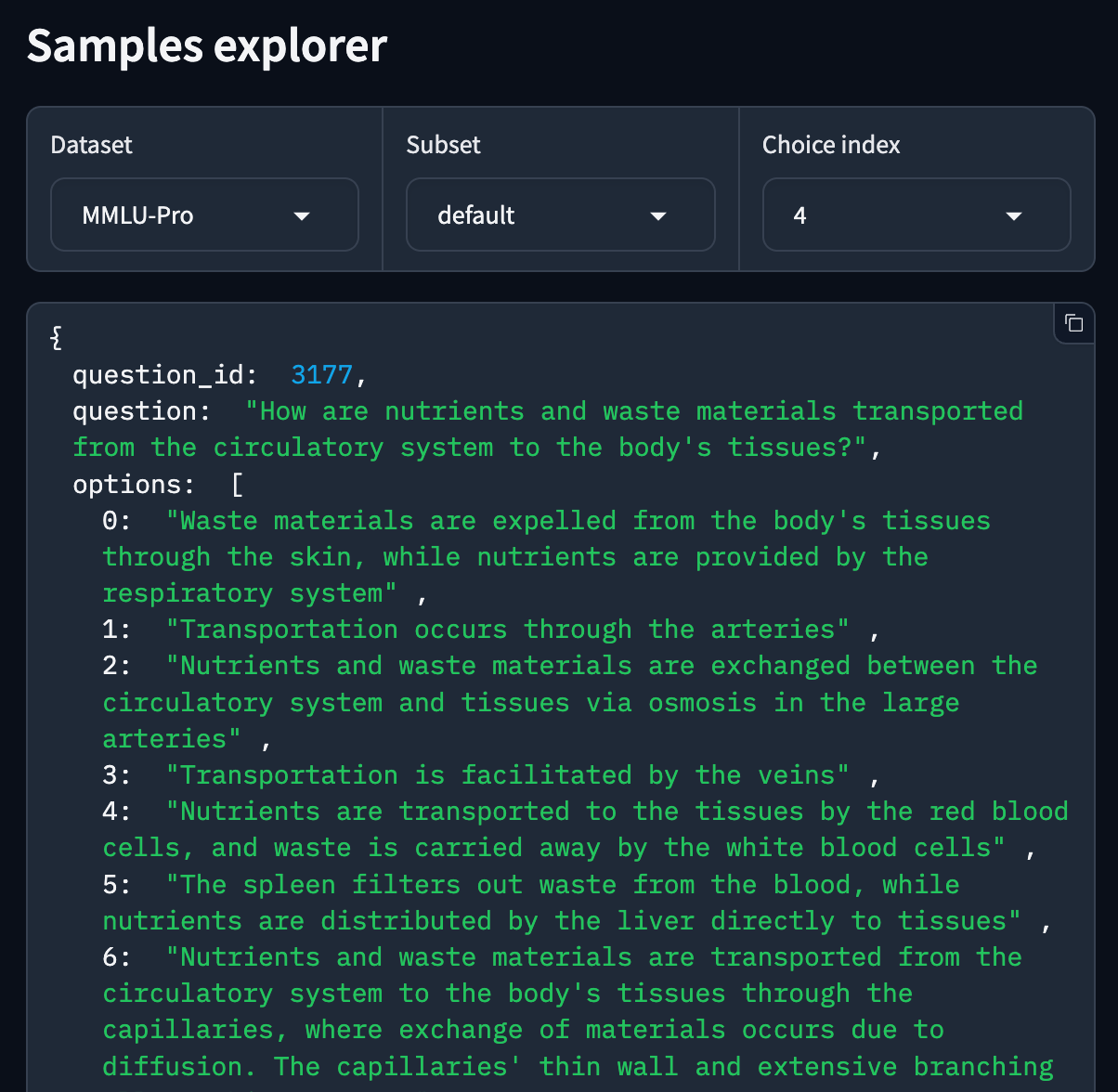
MMLU-Pro (Massive Multitask Language Understanding, paper)
World knowledge
10-choice QA
GPQA (Google-Proof Q&A, paper)
Crafted by PhD-level of their field
Near impossible for a layperson to get answer by internet search
MuSR (Multistep Soft Reasoning, paper)
Fun new dataset made of algorithmically generated complex problems of around 1K words in length
Examples: murder mysteries, object placement questions, or team allocation optimizations
MATH (Mathematics Aptitude Test of Heuristics, Level 5 subset, paper)
Hard high-school math problems, formatted with Latex for equation and Asymptote for figures
This benchmark can test for output formatting.
IFEval (Instruction Following Evaluation, paper)
Meant for instruction following test; the content is less important.
BBH (Big Bench Hard, paper)
Multistep arithmetic and algorithmic reasoning (understanding boolean expressions, SVG for geometric shapes, etc), language understanding (sarcasm detection, name disambiguation, etc), and some world knowledge
One Metric from these Benchmarks
HuggingFace also redefined a way to compare LLMs with a single metric, which is calculated based on these aforementioned benchmarks. The new way perform better ‘normalization’ before simple averaging. This could compare the LLMs more fairly. More detail can be found here.
Implications to LLM-app builders
Major providers might use these new benchmarks proposed by HuggingFace.
LMSys’s Chatbot Arena might as well adopt the new evaluation set.
If you are providing LLM, consider using these new benchmarks.